Unifying Inductive, Cross-Domain, and Multimodal Learning for Robust and Generalizable Recommendation
Chanyoung Chung, Kyeongryul Lee, Sunbin Park, Joyce Jiyoung Whang
International Workshop on Multimodal Generative Search and Recommendation (MMGenSR) Workshop at ACM International Conference on Information and Knowledge Management (CIKM) 2025
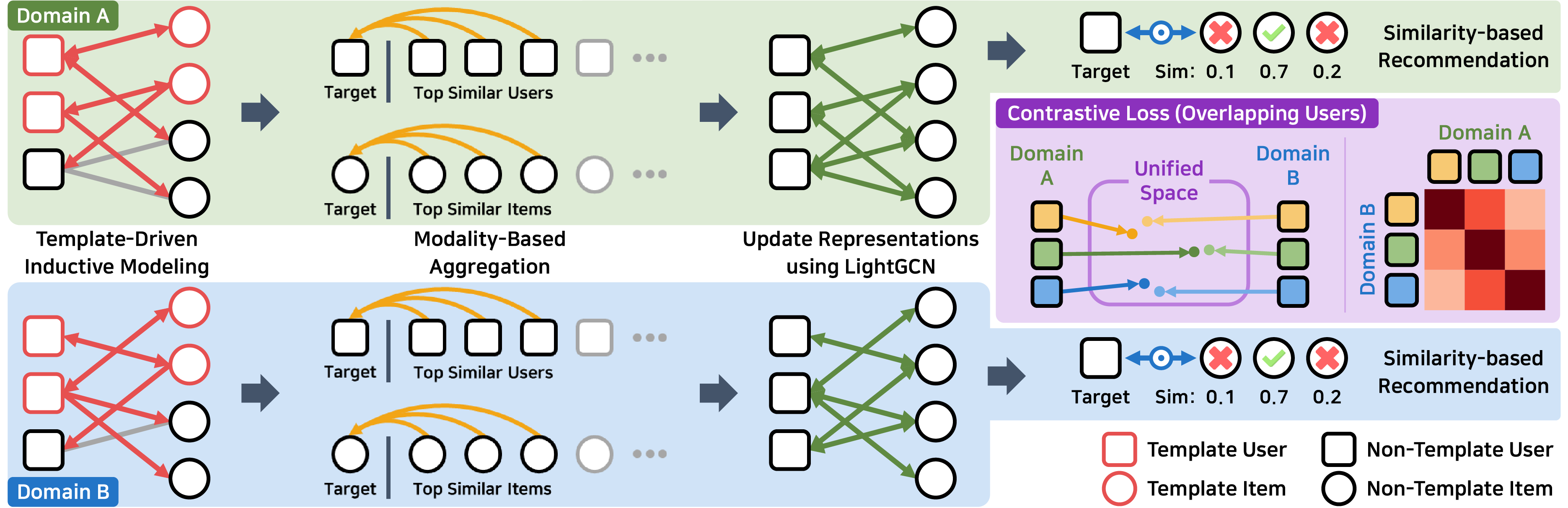
Recommender systems have long been built upon the modeling of interactions between users and items, while recent studies have sought to broaden this paradigm by generalizing to new users and items, incorporating diverse information sources, and transferring knowledge across domains. Nevertheless, these efforts have largely focused on individual aspects, hindering their ability to tackle the complex recommendation scenarios that arise in daily consumptions across diverse domains. In this paper, we present MICRec, a unified framework that fuses inductive modeling, multimodal guidance, and cross-domain transfer to capture user contexts and latent preferences in heterogeneous and incomplete real-world data. Moving beyond the inductive backbone of INMO, our model refines expressive representations through modality-based aggregation and alleviates data sparsity by leveraging overlapping users as anchors across domains, thereby enabling robust and generalizable recommendation. Experiments show that MICRec outperforms 12 baselines, with notable gains in domains with limited training data.
Unifying Inductive, Cross-Domain, and Multimodal Learning for Robust and Generalizable Recommendation
Chanyoung Chung, Kyeongryul Lee, Sunbin Park, Joyce Jiyoung Whang
International Workshop on Multimodal Generative Search and Recommendation (MMGenSR) Workshop at ACM International Conference on Information and Knowledge Management (CIKM) 2025
Recommender systems have long been built upon the modeling of interactions between users and items, while recent studies have sought to broaden this paradigm by generalizing to new users and items, incorporating diverse information sources, and transferring knowledge across domains. Nevertheless, these efforts have largely focused on individual aspects, hindering their ability to tackle the complex recommendation scenarios that arise in daily consumptions across diverse domains. In this paper, we present MICRec, a unified framework that fuses inductive modeling, multimodal guidance, and cross-domain transfer to capture user contexts and latent preferences in heterogeneous and incomplete real-world data. Moving beyond the inductive backbone of INMO, our model refines expressive representations through modality-based aggregation and alleviates data sparsity by leveraging overlapping users as anchors across domains, thereby enabling robust and generalizable recommendation. Experiments show that MICRec outperforms 12 baselines, with notable gains in domains with limited training data.
VISTA: Visual-Textual Knowledge Graph Representation Learning
Jaejun Lee, Chanyoung Chung, Hochang Lee, Sungho Jo, Joyce Jiyoung Whang
Findings of Empirical Methods in Natural Language Processing (Findings of EMNLP) 2023
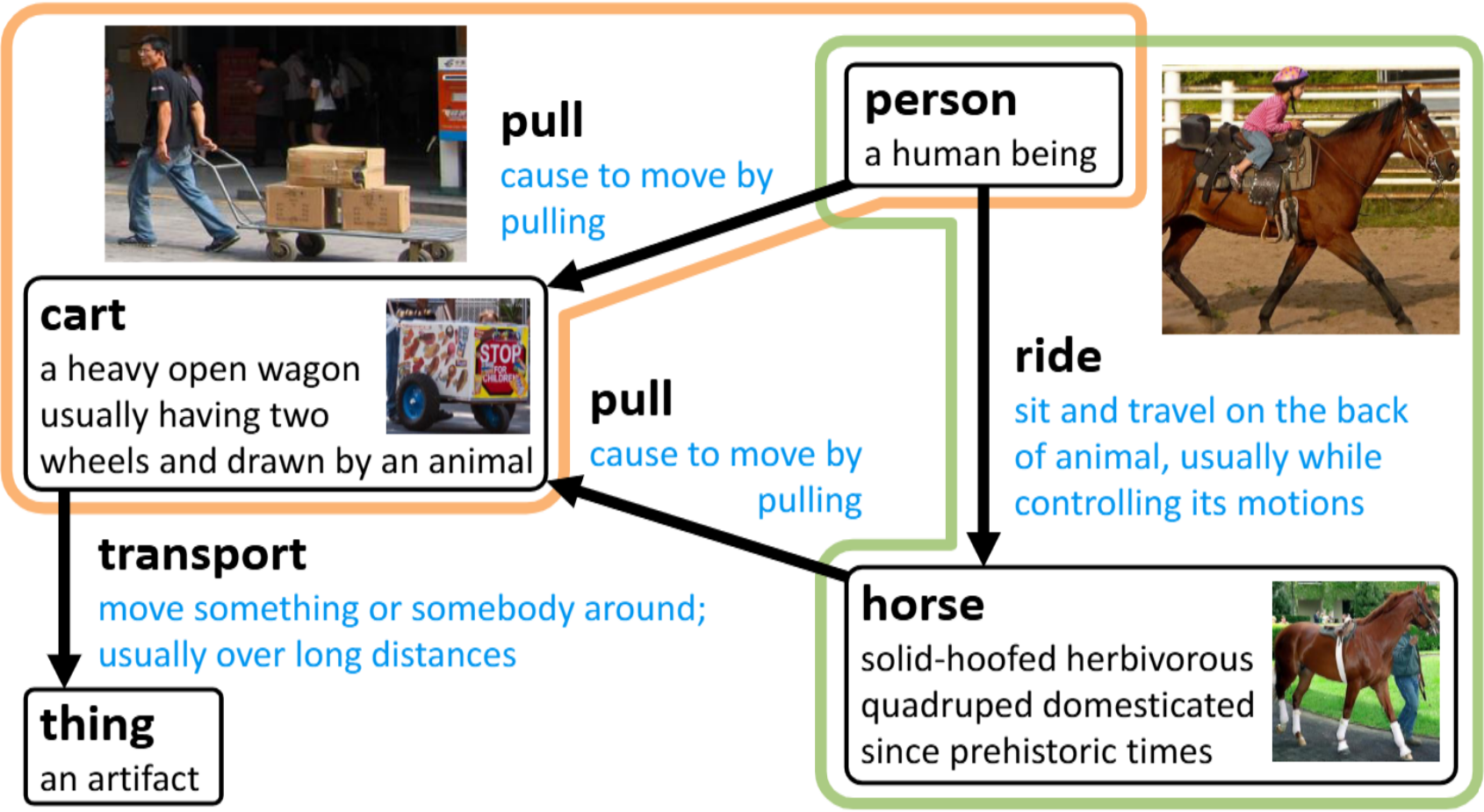
Knowledge graphs represent human knowledge using triplets composed of entities and relations. While most existing knowledge graph embedding methods only consider the structure of a knowledge graph, a few recently proposed multimodal methods utilize images or text descriptions of entities in a knowledge graph. In this paper, we propose visual-textual knowledge graphs (VTKGs), where not only entities but also triplets can be explained using images, and both entities and relations can accompany text descriptions. By compiling visually expressible commonsense knowledge, we construct new benchmark datasets where triplets themselves are explained by images, and the meanings of entities and relations are described using text. We propose VISTA, a knowledge graph representation learning method for VTKGs, which incorporates the visual and textual representations of entities and relations using entity encoding, relation encoding, and triplet decoding transformers. Experiments show that VISTA outperforms state-of-the-art knowledge graph completion methods in real-world VTKGs.
VISTA: Visual-Textual Knowledge Graph Representation Learning
Jaejun Lee, Chanyoung Chung, Hochang Lee, Sungho Jo, Joyce Jiyoung Whang
Findings of Empirical Methods in Natural Language Processing (Findings of EMNLP) 2023
Knowledge graphs represent human knowledge using triplets composed of entities and relations. While most existing knowledge graph embedding methods only consider the structure of a knowledge graph, a few recently proposed multimodal methods utilize images or text descriptions of entities in a knowledge graph. In this paper, we propose visual-textual knowledge graphs (VTKGs), where not only entities but also triplets can be explained using images, and both entities and relations can accompany text descriptions. By compiling visually expressible commonsense knowledge, we construct new benchmark datasets where triplets themselves are explained by images, and the meanings of entities and relations are described using text. We propose VISTA, a knowledge graph representation learning method for VTKGs, which incorporates the visual and textual representations of entities and relations using entity encoding, relation encoding, and triplet decoding transformers. Experiments show that VISTA outperforms state-of-the-art knowledge graph completion methods in real-world VTKGs.
Representation Learning on Hyper-Relational and Numeric Knowledge Graphs with Transformers
Chanyoung Chung*, Jaejun Lee*, Joyce Jiyoung Whang (* equal contribution)
ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD) 2023
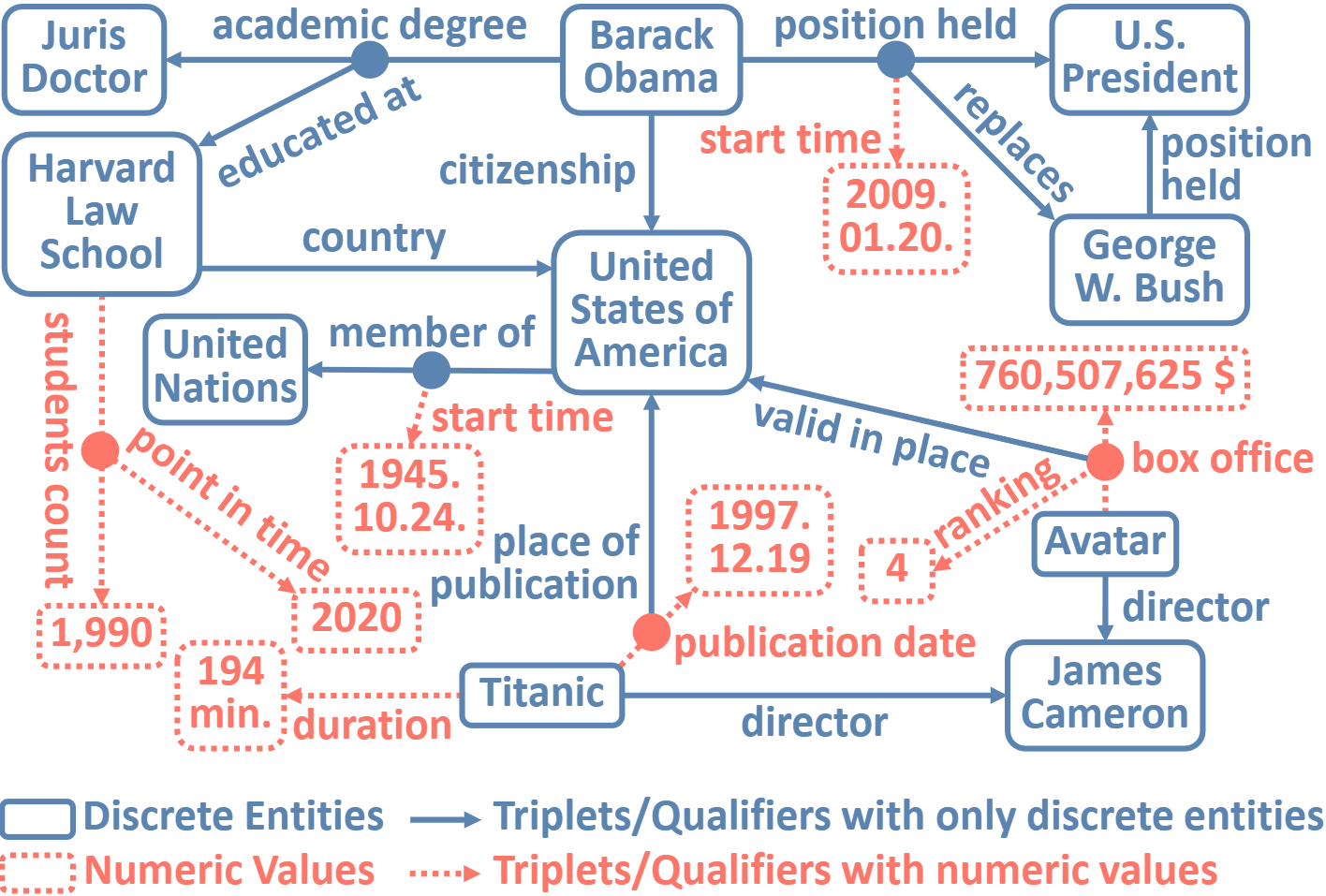
In a hyper-relational knowledge graph, a triplet can be associated with a set of qualifiers, where a qualifier is composed of a relation and an entity, providing auxiliary information for the triplet. While existing hyper-relational knowledge graph embedding methods assume that the entities are discrete objects, some information should be represented using numeric values, e.g., (J.R.R., was born in, 1892). Also, a triplet (J.R.R., educated at, Oxford Univ.) can be associated with a qualifier such as (start time, 1911). In this paper, we propose a unified framework named HyNT that learns representations of a hyper-relational knowledge graph containing numeric literals in either triplets or qualifiers. We define a context transformer and a prediction transformer to learn the representations based not only on the correlations between a triplet and its qualifiers but also on the numeric information. By learning compact representations of triplets and qualifiers and feeding them into the transformers, we reduce the computation cost of using transformers. Using HyNT, we can predict missing numeric values in addition to missing entities or relations in a hyper-relational knowledge graph. Experimental results show that HyNT significantly outperforms state-of-the-art methods on real-world datasets.
Representation Learning on Hyper-Relational and Numeric Knowledge Graphs with Transformers
Chanyoung Chung*, Jaejun Lee*, Joyce Jiyoung Whang (* equal contribution)
ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD) 2023
In a hyper-relational knowledge graph, a triplet can be associated with a set of qualifiers, where a qualifier is composed of a relation and an entity, providing auxiliary information for the triplet. While existing hyper-relational knowledge graph embedding methods assume that the entities are discrete objects, some information should be represented using numeric values, e.g., (J.R.R., was born in, 1892). Also, a triplet (J.R.R., educated at, Oxford Univ.) can be associated with a qualifier such as (start time, 1911). In this paper, we propose a unified framework named HyNT that learns representations of a hyper-relational knowledge graph containing numeric literals in either triplets or qualifiers. We define a context transformer and a prediction transformer to learn the representations based not only on the correlations between a triplet and its qualifiers but also on the numeric information. By learning compact representations of triplets and qualifiers and feeding them into the transformers, we reduce the computation cost of using transformers. Using HyNT, we can predict missing numeric values in addition to missing entities or relations in a hyper-relational knowledge graph. Experimental results show that HyNT significantly outperforms state-of-the-art methods on real-world datasets.

InGram: Inductive Knowledge Graph Embedding via Relation Graphs
Jaejun Lee, Chanyoung Chung, Joyce Jiyoung Whang
International Conference on Machine Learning (ICML) 2023
Inductive knowledge graph completion has been considered as the task of predicting missing triplets between new entities that are not observed during training. While most inductive knowledge graph completion methods assume that all entities can be new, they do not allow new relations to appear at inference time. This restriction prohibits the existing methods from appropriately handling real-world knowledge graphs where new entities accompany new relations. In this paper, we propose an INductive knowledge GRAph eMbedding method, InGram, that can generate embeddings of new relations as well as new entities at inference time. Given a knowledge graph, we define a relation graph as a weighted graph consisting of relations and the affinity weights between them. Based on the relation graph and the original knowledge graph, InGram learns how to aggregate neighboring embeddings to generate relation and entity embeddings using an attention mechanism. Experimental results show that InGram outperforms 14 different state-of-the-art methods on varied inductive learning scenarios.
InGram: Inductive Knowledge Graph Embedding via Relation Graphs
Jaejun Lee, Chanyoung Chung, Joyce Jiyoung Whang
International Conference on Machine Learning (ICML) 2023
Inductive knowledge graph completion has been considered as the task of predicting missing triplets between new entities that are not observed during training. While most inductive knowledge graph completion methods assume that all entities can be new, they do not allow new relations to appear at inference time. This restriction prohibits the existing methods from appropriately handling real-world knowledge graphs where new entities accompany new relations. In this paper, we propose an INductive knowledge GRAph eMbedding method, InGram, that can generate embeddings of new relations as well as new entities at inference time. Given a knowledge graph, we define a relation graph as a weighted graph consisting of relations and the affinity weights between them. Based on the relation graph and the original knowledge graph, InGram learns how to aggregate neighboring embeddings to generate relation and entity embeddings using an attention mechanism. Experimental results show that InGram outperforms 14 different state-of-the-art methods on varied inductive learning scenarios.
Learning Representations of Bi-level Knowledge Graphs for Reasoning beyond Link Prediction
Chanyoung Chung, Joyce Jiyoung Whang
AAAI Conference on Artificial Intelligence (AAAI) 2023
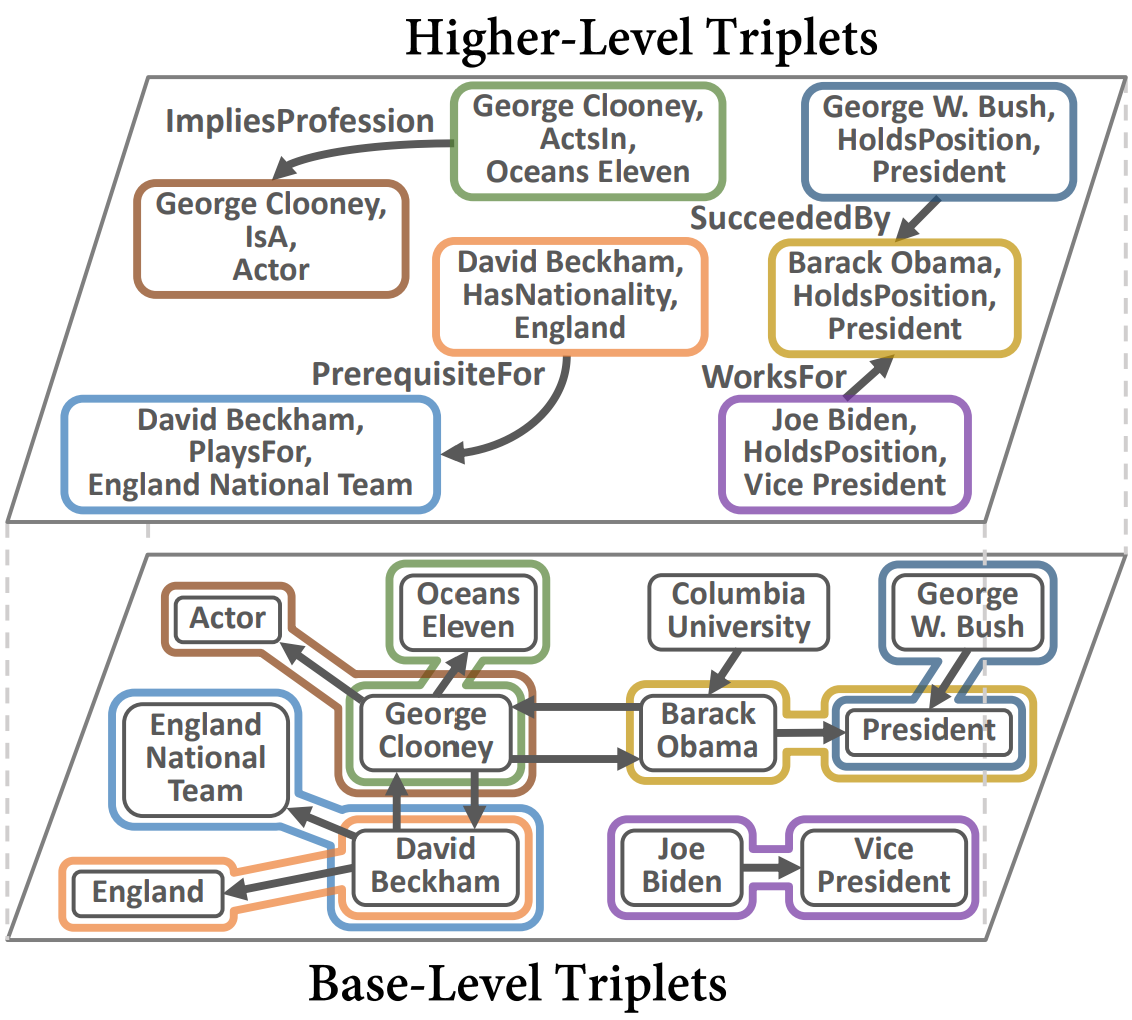
Knowledge graphs represent known facts using triplets. While existing knowledge graph embedding methods only consider the connections between entities, we propose considering the relationships between triplets. For example, let us consider two triplets $T_1$ and $T_2$ where $T_1$ is (Academy_Awards, Nominates, Avatar) and $T_2$ is (Avatar, Wins, Academy_Awards). Given these two base-level triplets, we see that $T_1$ is a prerequisite for $T_2$. In this paper, we define a higher-level triplet to represent a relationship between triplets, e.g., $\langle T_1$, PrerequisiteFor, $T_2 \rangle$ where PrerequisiteFor is a higher-level relation. We define a bi-level knowledge graph that consists of the base-level and the higher-level triplets. We also propose a data augmentation strategy based on the random walks on the bi-level knowledge graph to augment plausible triplets. Our model called BiVE learns embeddings by taking into account the structures of the base-level and the higher-level triplets, with additional consideration of the augmented triplets. We propose two new tasks: triplet prediction and conditional link prediction. Given a triplet $T_1$ and a higher-level relation, the triplet prediction predicts a triplet that is likely to be connected to $T_1$ by the higher-level relation, e.g., $\langle T_1$, PrerequisiteFor, ?$\rangle$. The conditional link prediction predicts a missing entity in a triplet conditioned on another triplet, e.g., $\langle T_1$, PrerequisiteFor, (Avatar, Wins, ?)$\rangle$. Experimental results show that BiVE significantly outperforms all other methods in the two new tasks and the typical base-level link prediction in real-world bi-level knowledge graphs.
Learning Representations of Bi-level Knowledge Graphs for Reasoning beyond Link Prediction
Chanyoung Chung, Joyce Jiyoung Whang
AAAI Conference on Artificial Intelligence (AAAI) 2023
Knowledge graphs represent known facts using triplets. While existing knowledge graph embedding methods only consider the connections between entities, we propose considering the relationships between triplets. For example, let us consider two triplets $T_1$ and $T_2$ where $T_1$ is (Academy_Awards, Nominates, Avatar) and $T_2$ is (Avatar, Wins, Academy_Awards). Given these two base-level triplets, we see that $T_1$ is a prerequisite for $T_2$. In this paper, we define a higher-level triplet to represent a relationship between triplets, e.g., $\langle T_1$, PrerequisiteFor, $T_2 \rangle$ where PrerequisiteFor is a higher-level relation. We define a bi-level knowledge graph that consists of the base-level and the higher-level triplets. We also propose a data augmentation strategy based on the random walks on the bi-level knowledge graph to augment plausible triplets. Our model called BiVE learns embeddings by taking into account the structures of the base-level and the higher-level triplets, with additional consideration of the augmented triplets. We propose two new tasks: triplet prediction and conditional link prediction. Given a triplet $T_1$ and a higher-level relation, the triplet prediction predicts a triplet that is likely to be connected to $T_1$ by the higher-level relation, e.g., $\langle T_1$, PrerequisiteFor, ?$\rangle$. The conditional link prediction predicts a missing entity in a triplet conditioned on another triplet, e.g., $\langle T_1$, PrerequisiteFor, (Avatar, Wins, ?)$\rangle$. Experimental results show that BiVE significantly outperforms all other methods in the two new tasks and the typical base-level link prediction in real-world bi-level knowledge graphs.
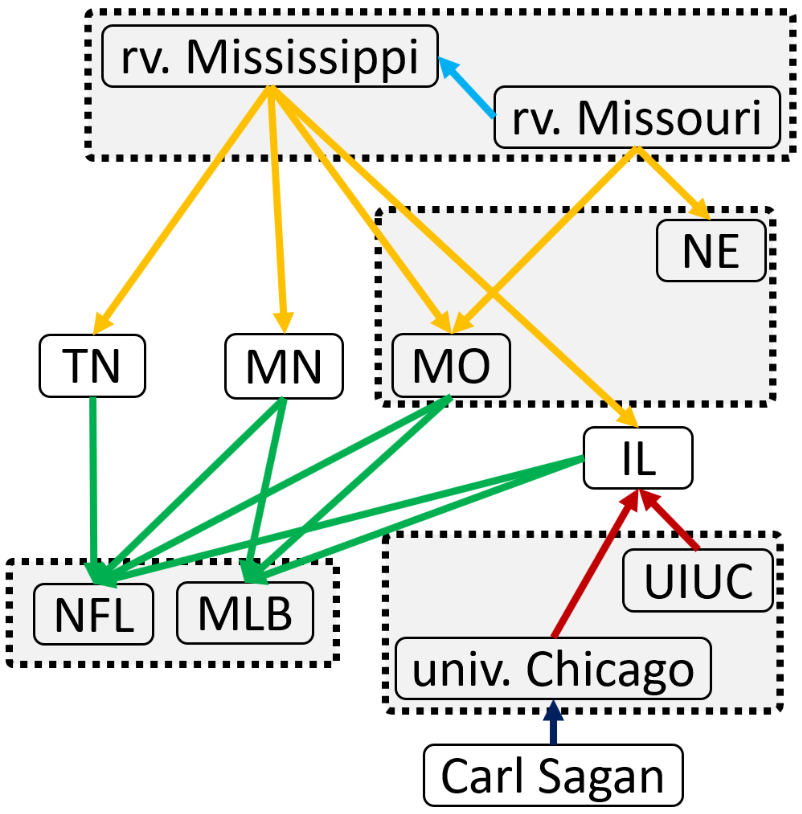
Knowledge Graph Embedding via Metagraph Learning
Chanyoung Chung, Joyce Jiyoung Whang
International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR) 2021
Knowledge graph embedding aims to represent entities and relations in a continuous feature space while preserving the structure of a knowledge graph. Most existing knowledge graph embedding methods either focus only on a flat structure of the given knowledge graph or exploit the predefined types of entities to explore an enriched structure. In this paper, we define the metagraph of a knowledge graph by proposing a new affinity metric that measures the structural similarity between entities, and then grouping close entities by hypergraph clustering. Without any prior information about entity types, a set of semantically close entities is successfully merged into one super-entity in our metagraph representation. We propose the metagraph-based pre-training model of knowledge graph embedding where we first learn representations in the metagraph and initialize the entities and relations in the original knowledge graph with the learned representations. Experimental results show that our method is effective in improving the accuracy of state-of-the-art knowledge graph embedding methods.
Knowledge Graph Embedding via Metagraph Learning
Chanyoung Chung, Joyce Jiyoung Whang
International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR) 2021
Knowledge graph embedding aims to represent entities and relations in a continuous feature space while preserving the structure of a knowledge graph. Most existing knowledge graph embedding methods either focus only on a flat structure of the given knowledge graph or exploit the predefined types of entities to explore an enriched structure. In this paper, we define the metagraph of a knowledge graph by proposing a new affinity metric that measures the structural similarity between entities, and then grouping close entities by hypergraph clustering. Without any prior information about entity types, a set of semantically close entities is successfully merged into one super-entity in our metagraph representation. We propose the metagraph-based pre-training model of knowledge graph embedding where we first learn representations in the metagraph and initialize the entities and relations in the original knowledge graph with the learned representations. Experimental results show that our method is effective in improving the accuracy of state-of-the-art knowledge graph embedding methods.